Description
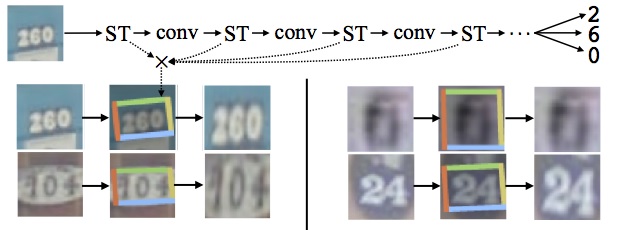
The spatial transformer networks proposed by Jaderberg et al. (https://arxiv.org/pdf/1506.02025.pdf) try to transform the image before passing to the CNN. This is different from other networks because it tries to modify the image before convolution. This network learns the parameters to transform the image. The parameters are learned for an affine transformation. By applying an affine transformation, spatial invariance is achieved. In the previous networks, spatial invariance was achieved by max-pooling layers. The placement of spatial transformer networks is shown as follows:
Potential Impacts of PV Integration on Distribution Networks

Reviews
There are no reviews yet.