Description
Inception-V3 was proposed by Szegedy et al. (https://arxiv.org/pdf/1409.4842.pdf) and introduced the concept of inception that has a better way of generalization. This was the architecture that won the ImageNet competition in 2014. It is geared towards efficiency for speed and size. It has 12 times lesser parameters than AlexNet. Inception is the micro-architecture on which a macro-architecture is built. Each hidden layer has a higher-level representation of the image. At each layer, we have an option of using pooling or other layers. Instead of using one type of kernel, inception uses several kernels. An average pooling is followed by various size convolutions and then they are concatenated.
The kernel parameters can be learned based on the data. Using several kernels, the model can detect small features as well as higher abstractions. The 1 x 1 convolution will reduce the feature and, hence, computations. This takes less RAM during inference. The following is the inception module in its simplest form where there are options of convolutions with various kernel sizes and pooling:
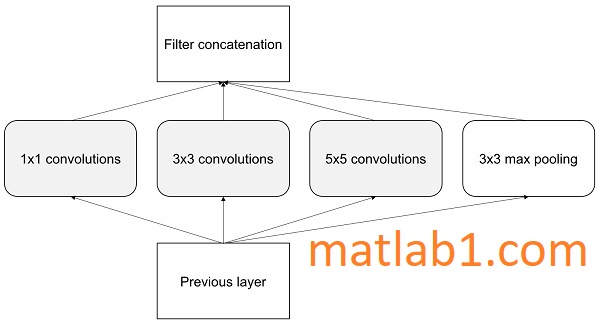
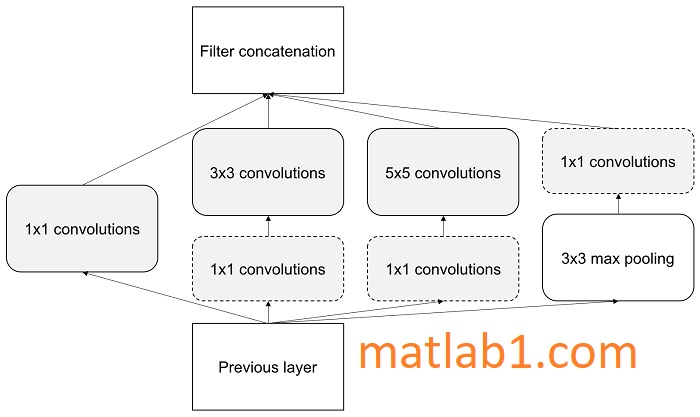
Notice that operations are happening in parallel, as opposed to AlexNet or VGG. The output volume is huge, and hence, 1 x 1 filters are introduced for dimensionality reduction. When the reduced dimensions are added to the architecture it becomes as follows:

The whole architecture of the model is as follows with all the bells and whistles:
The Google Inception-V3 model
There are nine inception modules with a total of 100 layers and they achieve good performance.
Modbus Monitoring for Networked Control Systems of Cyber-Defensive Architecture
Reviews
There are no reviews yet.