The number of tweets collected for participating users varies widely, as shown in Figure. As discussed in subsection only about the most recent 3200 tweets can be collected from a user.The average of 1538 tweets collected per user and median of 1065 suggest that for as many users for whom the number of tweets downloaded reached the maximum number (3200), there were equally as many who had published under a thousand tweets. Additionally, several users only
contributed a few tweets, and a few contributed none.
On the tweet level, most tweets had a token count in the teens or low twenties, as shown in Figure . This token count includes both word tokens and punctuation tokens. A punctuation token includes standard clausal punctuation, such as commas and periods, as well as emoticons and other only-punctuation elements in tweets. Additionally, the token count is based on tokenization by the NLTK punkt tokenizer, which splits contractions into two word tokens, so a space-based token count would have been a bit lower. Word tokens are the set of unigram tokens left over when the punctuation tokens are removed. As indicated by Figures , an average tweet might be a single sentence, with two punctuation marks and 14 word tokens. The most extreme outlier consists of a three character interjection (“YAY”), followed by 137 exclamation points. The tokenizer splits standard punctuation, so this greatly increased the token count by splitting each of the 137 exclamation marks into its own token. The amount of punctuation tokens in a tweet is generally below 5, suggesting that users avoid punctuation, except where necessary. Token counts.
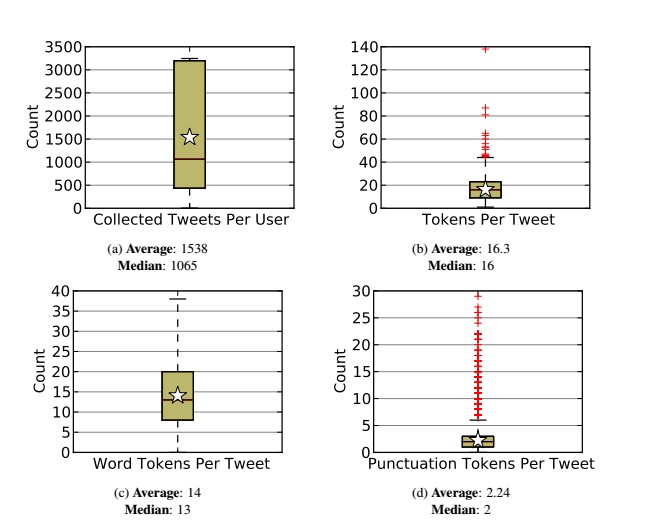
Tweet and token distributions. Stars mark the average values. The bar in the middle
of the box marks the median value (50th percentile), and the box extends to the edge of the 25th
and 75th percentiles. Tokens is a count of the total tokens of a tweet, as defined in subsection
Word token counts exclude tokens made up entirely of punctuation characters. The top 4 points
(137, 80, 48, and 47) are omitted from Figure for readability
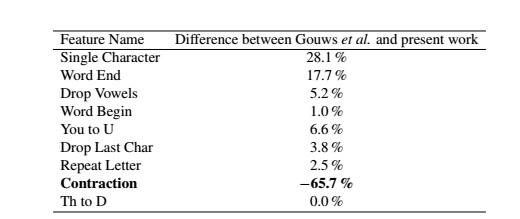
Difference between Gouws et al. and present work
Feature names and the difference of relative percentages found in the collected data set and
the work of Gouws et al. Differences shown are equivalent to subtracting the present work’s
results from those of Gouws et al. in Table . A notable difference is for the Contraction feature
(bolded), which accounted for a larger percentage of the detected word and phrase abbreviations in
the present work than in the work of Gouws et al.. In all other cases, the percentages in the present
work were lower than those in the work of Gouws et al..
and examples of average tweets and outliers are shown in Table 3 and Table 4, respectively.
As shown in Table 5, the distribution of abbreviation pattern features in the collected data set
is very different from those reported by Gouws et al. . While Gouws reported 90% coverage
with the 9 defined abbreviation types with a large Twitter data set, those types only cover ![]()
of the found abbreviation patterns in this data set. There are several reasons for this that could
be contributing factors, most notably that the algorithmic definition of the abbreviation patterns
may not have been consistent between the work of Gouws et al. and this work. Additionally, the
data set primarily captures people who have completed some level of college (see subsection 6.2
and Figure 8c). These more educated persons appear at a higher rate in the collected data set than
other studies have indicated . Many collected tweets are written in mostly standard English
with standard English syntax. Newer slang and various context-specific tokens, which may be
considered standard to a human reading or writing the collected tweets, would not have shown up
in the LA Times corpus or Han and Baldwin’s tweet corpus used to train the sentence normalizer
used in this study. As such, many tokens are replaced with unnecessary substitutions, and decoding
the lattice into a normalized sentence will augment tokens around any that were considered OOV.
This creates anomalous abbreviation patterns that do not fit into the defined categories at a higher
rate than a more general Twitter corpus, such as that used by Gouws et al., in which users utilize
word and phrase abbreviations more frequently.
