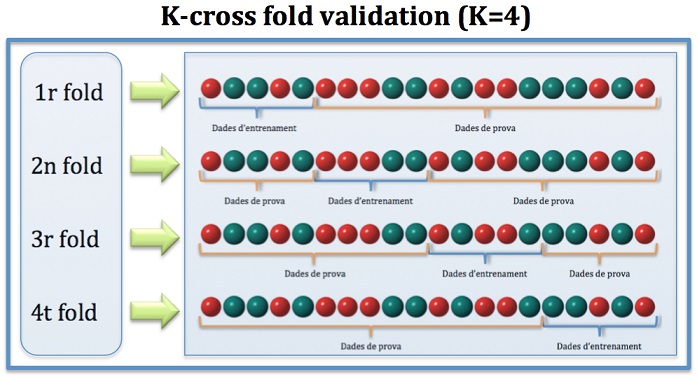
A k-fold cross validation technique is used to minimize the overfitting or bias in the predictive modeling techniques used in this study. k-Fold cross validation is used with decision tree and neural network with MLP and RBF to generate more flexible models to reduce overfitting or underfitting.
The complete dataset R is randomly split into k-mutually exclusive subsets or folds of approximately equal size . In classification model each of the k-subsets are trained and tested k times.
One of the k-subsets is used as the test set and the other k-1 subsets are used as training dataset.
Then the overall accuracy is calculated as the average of the k individual accuracy measures. All the machine learning techniques in this study use 10- fold cross validation.

Cross-Validation