The data analysis function had to look up the contents of the hashtag in several dictionaries: a New Oxford American dictionary that is available by default on all instances of MAC OS X Mountain Lion, and a CELEX2 dictionary of English (CELEX2,1996). The order of the lookup was the following: if the contents of the hashtag were absent from the Oxford American dictionary, a lookup was performed using the CELEX2 dictionary. If the contents of the hashtag were absent from CELEX2 as well, the contents of the hashtag were subjected to several stemming procedures prior to additional lookup attempts. Figure 8 illustrates the stemming process flowchart.
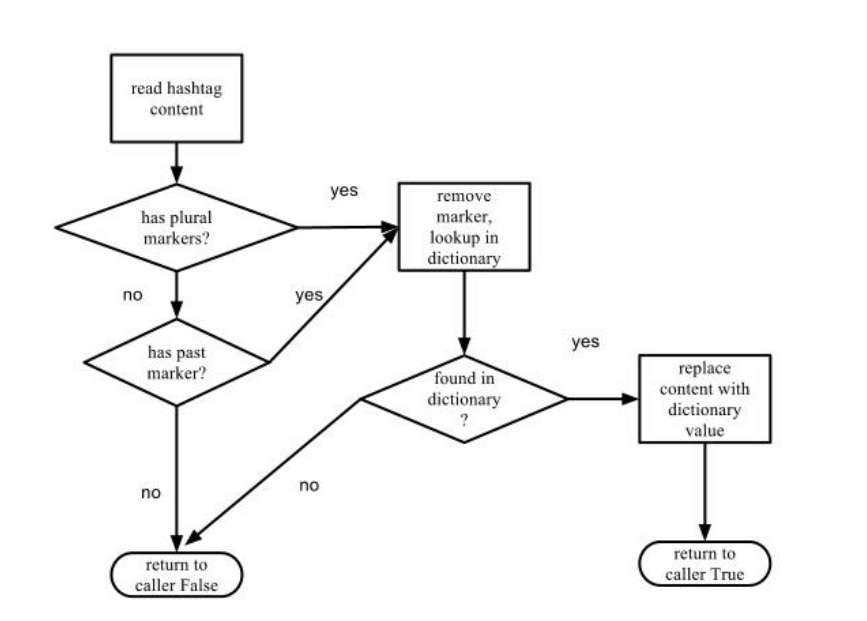
Stemming Flowchart
The stemming attempts were performed by the following strategy: if the hashtag content contained any form of English plural markers such as ‘-s’, ‘-es’, ‘-ies’, the plural marker was removed and a dictionary lookup was attempted with the new string. If the new string was found in the dictionary, the original hashtag content was replaced by the stemmed content. If the new string was not found in the dictionary, the content was examined to determine whether a past marker such as ‘-ed’ was found. In the case a past marker was found, the content was stripped of the past marker and a dictionary lookup was attempted with the new string. If the new string was found in a dictionary, the hashtag content was replaced by the new string. In all cases of dictionary lookup the dictionaries that were used were New Oxford American dictionary and a CELEX2 dictionary. After all the stemming and lookup attempts had failed, the working hypothesis was that the hashtag value was not a single word that had been grammatically modified. The next working assumption was that the value of the hashtag was a combination of several words concatenated together – #sogood would be one such example. While attempting to segment a hashtag into words, an approach utilizing word frequency data and Zipf’s law was used. Zipf’s law postulates “the distribution of word frequencies in English, if the words are aligned according to their ranks, is an inverse power law with the exponent very close to 1.” (Li, 1992). According to Goetz (as cited in Weisstein, 2012), given the number of different words
R, the probability of encountering a word with the rank of r is :
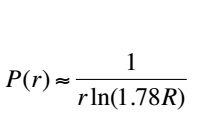
1
€ Assuming independence between words, the optimal segmentation would be the one where the product of the probability of individual words is maximized. A list of words with their frequencies was assembled based on Wikipedia texts (Wiktionary Frequency Lists, 2012). The programmatic component that was performing the analysis of a hashtag value was attempting to produce a list of potential candidates that could be combined into the existing string based on maximizing the probability of each word in a string. In the event that the programmatic component was not able to suggest such a list of potential words, an empty list structure was returned to the calling function. If, on the other hand, the analyzing component was able to find a list of words that could be concatenated in order to produce the original value, a list structure containing those words was returned to the calling function. In the case where an empty list was returned to the calling function, the working hypothesis was that the value of the hashtag that was being analyzed might be either an acronym or a slang term. Those cases required additional disambiguation attempts utilizing online resources. The online resources used for the purpose were Tagdef (www.tagdef.com) and Urban Dictionary (www.urbandictionary.com). Tagdef is a web site that provides Twitter users with information regarding hashtags. The site allows users to add new hashtag meanings as well as provide additional meanings for already existing hashtags. The site provides “the definition for all the hashtags. As the name suggests, Tagdef is like a dictionary of hashtags where you can find meaning of all hashtags. “ (Bindra, 2012). Users can express their opinion as to the correctness of meaning of the hashtags by voting for or against existing translations of hashtags. Additionally, Tagdef displays a list of trending hashtags from Twitter, the most popular hashtags on Twitter at any given time, while specifically marking those that have not been translated yet. Tagdef has a publicly available API that was used by the programmatic component to translate the hashtag value in those cases where previous disambiguation attempts did not produce positive results. If the response from Tagdef was negative, that is the hashtag value was not found on Tagdef, a working assumption at this stage was that the value might be a slang word, and a final attempt at disambiguation using Urban Dictionary was made by the programmatic component. Urban Dictionary is an online dictionary of slang words, phrases, and acronyms. According to Urban Dictionary, as of September 8th 2012, the site contained 6,745,221 definitions (Urban Dictionary, 2012). There is a publicly available third party API that can be accessed programmatically and that is available at Urban Scraper (urbanscraper.herokuapp.com). In the case of negative results for the lookup of the hashtag value on Urban Dictionary, no further attempts at disambiguation were made. For the values that were not found, a string “NONE” was used to mark those hashtags that were not to be included in the sentiment score calculations. If the value of the hashtag was found by any of the previously described means, it was replaced with the translated value when different from the original hashtag value. From this point on, the sentiment score calculations that included the hashtag values or their translations could be performed for the tweets that were collected in the data collection stage as described above.
Sentiment Score Calculation. The sentiment score calculation was performed for the tweets collected in the data collection stage in the following manner: for each component in a tweet that was to be considered for sentiment score calculation such as a word or hashtag, a lookup in the AFINN-111 file (Nielsen, 2011) was performed. The result of the lookup was a numeric score that was associated with the word. If the word was not found in AFINN-111 file, the score of 0 was assigned to the word. The AFINN-111 sentiment-rating file contains 2,477 words and phrases and their sentiment valence ratings range from -5 to +5. Unlike in the original ANEW version, inflection variants and slang words are also included (Nielsen, 2011). Since each tweet can contain more than one word, the potential valence rating for a tweet can range from (-5)∗N to (+5)∗N where N is the number of words in a tweet. The scores for each constituent of a tweet were looked up in AFINN-111 file and summed up to calculate the sentiment score of the whole tweet. In order to be able to analyze the relative contribution of the hashtag value to the overall sentiment score of the tweet, a sentiment score was computed twice for each tweet. In the first calculation, the hashtag values were ignored such that if a tweet T consisted of a collection of words {j0, j1,… jn} and a collection of hashtags {h0, h1, …hn}, the sentiment score was calculated such that s(T) = Σs(ji) for ji ∈ T. In the second calculation, the hashtag was included in the sentiment score calculation – if a tweet T consisted of a collection of words {j0, j1, … jn} and a collection of hashtags {h0, h1, …hn}, the sentiment score was calculated such that s(T) = Σs(j) + Σs(h) for ji, hj ∈ T. The values of the hashtag were disambiguated and translated where needed using the methods described above in the section Hashtag Analysis. In those cases where the values of the hashtags were translated and replaced by the hashtag analysis function, the sentiment score calculations were performed on the new values of the hashtag that was substituted for the original values.
Establishing a Control Group
In order to evaluate the validity of the sentiment scores produced by the programmatic component, a comparison between those and the scores provided by human raters is the accepted procedure. Due to the significant number of tweets collected, it was not practical to have human raters score all the tweets for their sentiment. One way around the issue would be to use a randomly selected subset of the tweets rated by human raters. Due to the lack of resources, however, obtaining and training human raters is beyond the means of this project. Therefore, the author provided the sample human ratings. The sentiment score component provided two scores for each tweet, one that included the hashtag contribution and another that did not include it. In cases where the scores were the same, we were able to conclude that the hashtag did not contribute any additional insight to the sentiment of the tweet’s author. Since the goal of this thesis was to investigate whether there is any contribution of the hashtag to the overall sentiment score of the tweet, it was beneficial to concentrate only on those tweets that had two different sentiment scores produced. Therefore, in cases where there was an observed difference between the two values, the programmatic component performing the sentiment score calculation appended those tweets to a separate file for future investigation or human rating. From the set of those a subset that is rated by the author was used to evaluate which of the sentiment scores that were produced by the sentiment scoring component was closer to the rates that human raters produced. The scores thus obtained were collected and compared to the scores generated for each of the sentiment score calculations by the programmatic component as described in the Sentiment Analysis section. The results of this process are presented and analyzed in Chapter 4. The data files are available at https://sites.google.com/site/thesis1data/
