CARLA (Car Learning to Act) [1] is the state-of-the-art simulator for autonomous driving research. CARLA provides a well-documented Python API for controlling various properties of simulations. The maximal freedom of customization makes it a useful tool for simulated data generation, scenario construction, and autopilot development.
Simulator Architecture
CARLA uses a client-server architecture. Clients connect to the server using an IP address and TCP ports. However, the definitions of the server and the client are different for different versions. In CARLA 0.8.x, the simulated world and a user controllable player run on the server. Only one client is allowed. The client is defined as the controller of the player. The client session can modify simulation properties, retrieve data and control the player. In contrast, the 0.9.x version is a multi-client system in which the server is the simulated world only and a client is not tied to any players. Multiple players can be programmatically controlled simultaneously.
CARLA updates its Python API very frequently. Updates used to change the units of measurements and coordinate systems. Being specific about the version is very important. This work discusses CARLA 0.9.10 unless specified otherwise.
The world is the root of the hierarchy and has access to almost all information. The world contains the actors, the map, the blueprint library, the snapshots, and the weather and traffic managers. The definition of an actor is broad. An actor can be a vehicle, a pedestrian, a sensor, a traffic light, a traffic sign or a spectator. An actor can be understood as an abstract class for every interactive element in the world.
The map contains the model of the world. The blueprint library is a collection of physical models of all types of actors. When an actor is created, a blueprint must be provided. Blueprints do not contain any information related to the world such as the location of an actor. The snapshots are a full description of the simulation at a frame including the states of all objects.
Synchronization is important at two independent places in the CARLA simulator. The first one is between the world clock and the simulation clock. It is necessary to clarify the relationship between the time passing in the simulated world and the time between two simulation steps. The simulation can be set to either fixed time-step or variable time-step. Fixed time-step means the time advancement in the simulated world is a fixed value regardless of how long the simulator takes to compute the next step. When variable time-step is used, the two clocks are synchronized. The other synchronization issue is due to the client-server architecture. CARLA supports two modes: asynchronous mode and synchronous mode. In asynchronous mode, the server updates and simulates the world as fast as possible. The optimal simulation performance is achieved while it creates a synchronization problem among different components interacting with a slow client. Inter-client synchronization is even more troublesome. In synchronous mode, the server waits for a tick to proceed with the simulation. In multi-client applications, there must be only one master client to tick. Otherwise, clients will be inconsistent with each other because the server moves on with every tick received without distinguishing the sources.
Operating a Client
The first step to initialize a client is to get a pointer to the world object host by the server so the client can make further interactions. When a client is started, no visual display is automatically created. The graphic interface has to be programmed by users if needed. A typical approach is to spawn a sensor in the world and display the image stream retrieved from the sensor. The world initialized by the server has an empty map. A client can populate the world by spawning actors. Actors will not be destroyed until the destructors are called explicitly even if the Python script of the client terminates.
Spawning an actor only requires a blueprint and a transform object. The transform class specifies the location and the orientation in a relative sense. The location and orientation of any other actor can be set to be the reference. This is useful when we want to attach a sensor to a vehicle. By default, the reference point is the origin of the world coordinate system. CARLA uses the Unreal Engine 4 and follows the engine’s Z-up left-handed coordinate system for its world coordinates. In actors’ local LIDAR coordinate system, the x (roll) axis points forward, the y (pitch) axis points right and the z (yaw) axis points up. The local camera coordinate system can be transformed from the LIDAR point cloud coordinate system by:
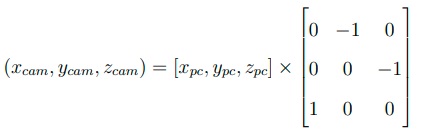
CARLA supports both automatic and manual control of actors. Vehicles have an autopilot mode which utilizes information from the simulation system rather than sensors. An intelligent controller is available for pedestrians. To manually control an actor, one can either use the built-in control module to set the throttle, brake, etc or just update the actor’s transform. The map class provides a list of waypoints, which are possible locations and orientations assuming normal driving behaviors. A handy function in the Python API can find the closest waypoint to an actor.
CARLA covers most sensor models that are popular for autonomous driving. The sensors are designed so that they take measurements with as little internal information of the world simulator as possible. The configurations of the sensors can be put into two groups: settings and physical model. Here, the discussion focuses on the sensors for perception. For the RGB camera, settings include image size. field of view, sensitivity (ISO value), etc. An example physical model parameter is the lens size.
CARLA sensors do not directly generate and save files in corresponding standard formats. Instead, CARLA designed data structures to contain the raw data and other useful attributes. The RGB, depth and semantic segmentation camera sensors all use the carla.Image class. The raw data of the three camera sensors is stored as 32-bit BGRA pixels with row-major ordering. For depth and semantic segmentation camera, decoding is required to convert the BGRA data into distance and tags. For example, the depth decoder is:
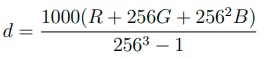
where d is the distance in meters. The output attributes that almost all sensors have are frame id, transform, timestamp and the settings that describe the output, such as field of view.
The LIDAR sensor is, particularly of our interest. CARLA provides two LIDAR sensors: semantic LIDAR and LIDAR. Only the latter is discussed here. CARLA uses ray-casting to implement the LIDAR sensor. Ray cast emissions detect mesh models in the Unreal Engine and generate the point cloud. The output raw data format is an array of 32-bit floats using row-major ordering. Every four values are one point pi = [xi , yi , zi , ri ], where xi , yi , zi are coordinates and ri is the reflectance or intensity. The intensity is a new feature since 0.9.10. The intensity is calculated instead of simulated. The definition of intensity in CARLA is:
![]()
where d is the distance, a is the tunable attenuation rate of wave propagation and I0 is a constant. The equation is taken from the definition of attenuation coefficient in telecommunications. When the intensity is in the input of a neural network as in equation (13), it actually represents a nonlinear combination of the three coordinates. The parameters for defining the LIDAR model are similar to those included in Table 1. Some other parameters are provided for achieving a better realism. A noise with user-defined standard deviation can be added to distance measurements while the angular positions are always perfect. Dropoff rates can be set to mimic the imperfection that a portion of emitted lasers are lost. The drop-off can be done randomly or based on intensity. The best practice is to set a general dropoff rate that drop points randomly together with a higher intensity-based dropoff rate to drop points with intensity lower than a selected threshold.
[1] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “CARLA: An open urban driving simulator,” in Proceedings of the 1st Annual Conference on Robot Learning, 2017, pp. 1–16.
