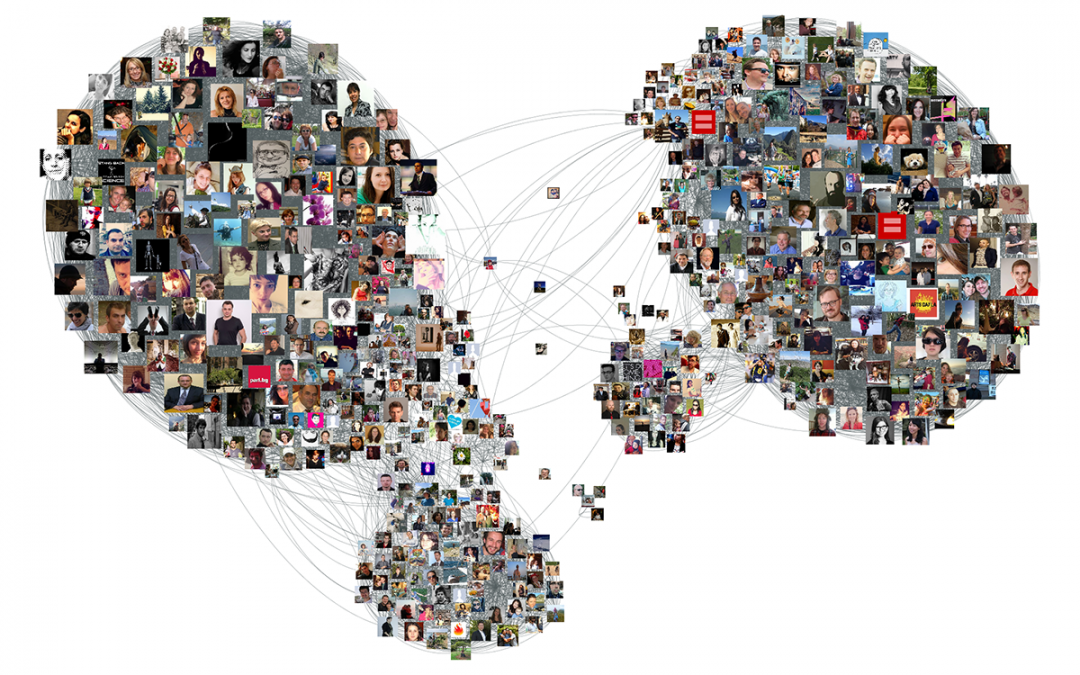
Techniques for Network Data Collection
Political scientists have applied a variety of approaches to collect data for statistical network analysis on political actors, including questionnaires, observations,experiments, and archival record analysis. In this section, I review current techniques for network data collection and discuss some limitations when applying these approaches to collecting network data in authoritarian and wartorn contexts.
Proposed method:
The method for data collection that is based on measuring social ties as the frequency with which people interact. Ties can be inferred based on cooccurrence, specically how often given individuals attend the same social events.
For political elites, these events include activities such as fundraisers, campaign banquets, political galas (e.g. dinners with foreign dignitaries), and ground breaking ceremonies. This type of network can be considered a subset of what is often referred to as an affiliation” network, wherein actors are tied to one another based on their affiliation with the same organizations or events The use of affiliation networks in sociology dates on gathering relational data on the social activities of eighteen Southern women through the use of newspapers and interviews to record how often the subjects attended the same social events. This approach is less common in political science studies of individual actors,1 though legislative co-sponsorship, caucus membership, and the Mexican board of directors networks can be considered asaffiliation networks. But in order to avoid the limitations of current techniques of data collection as identied above, a new approach to feasible network data collection is needed.
algorithm for Google Correlations :
1. Create list of individuals in network population (n)
2. Specify search criteria
3. Iteratively search pairs of individuals (i, j)
4. Record number of unique articles paired individuals appear in together(Pg2G cijg)
5. Randomly sample individual page results and calibrate search keywords accordingly
6. Repeat 2-5 until randomly sampled pages are appropriate as desired
Importantly, the search criteria in step 2 are used to capture individuals appearing in relevant events and reduce repetition of media stories by restricting site domains. Step 5 is critical to ensuring that the search criteria are appropriate,similar to the procedure in human-assisted text analysis algorithms. Here, the researcher combs through randomly sampled pages to determine if the resulting pages capture co-occurrence at events. This is done by randomly sampling the JSON through-put that serves as an intermediary of the scraping procedure performed in the perl code shown in the appendix. Specifically, each search using the Google Search API runs through a JSON le with page names, URLs, and two-line snippets from the top 500 results. A section of one such le is shown in Figure 3. By looking at the two-line snippets in particular, the researcher can determine whether or not the page is appropriate to the search.
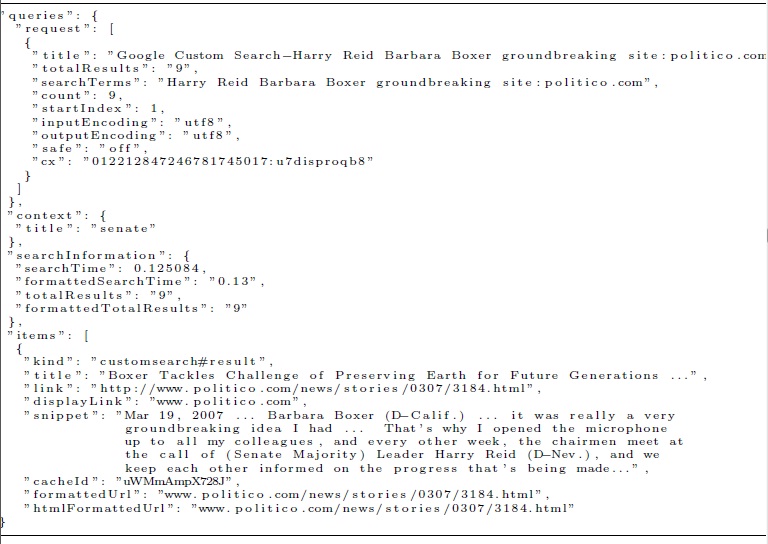
Figure 3: Example JSON through-put file using the Google search algorithm fora site search of U.S. Senators Barbara Boxer and Harry Reid with the keyword \groundbreaking” and a domain restriction to politico.com.
example of Google Correlations :
a simple search for \Harry Reid” and \Barbara Boxer” | without
any site restrictions or additional keywords | yields \About 320,000 results” but after clicking through to the last page of search results, this number dwindles to\About 349 results”.I overcome this page-counting problem by eschewing the collection of page hits via web-scraping of the html results page. Instead, I capture the total number of page hits based on the JSON through-put (as shown in Figure 3) provided by the Google Custom Search API. This approach provides an accurate count of total pages provided the total number of such pages is below 500, which is true for all pair-wise searches (with site restrictions and keywords) conducted in this paper.For searches that will likely result in more than 500 page results, the researcher must turn to ad hoc solutions such as \capping” search results above 1,000 ( et al.) or designing scraping algorithms that will \click-through” to the nal page of results and record the total number of resulting page hits. An additional option is to use sampling methods to generate \sample hits” based on a random sample of web pages from the first three to four pages of results | these initial pages theoretically represent the \best” results from a given search following the prioritization of pages established by the Google PageRank algorithm
