NOSQL Databases
For over decades, relational databases have been used to store structured data. The data is sub-divided into groups, referred to as tables (Vaish, 2013). The tables store well-defined units of data in terms of type, size, and other constraints. Each unit of data is known as a column while each unit of the group is known as a row. The columns may have relationships defined across
themselves, for example parent-child, and hence the name relational databases. And because consistency is one of the critical factors, scaling horizontally is a challenging task.
NOSQL.
With the growth of big web applications, research has poured into handling data at scale. One of the outputs of these studies is non-relational database, in general referred to as NoSQL database. One of the main problems that a NoSQL database solves is scale, among others (Vaish, 2013).Clearly NoSQL databases don’t use SQL. But most of them do have query languages, and it makes sense for them to be similar to SQL in order to make them easier to learn. An important characteristic of these databases is that they are generally open-source projects. Although the term NoSQL is frequently applied to closed-source systems, there’s a notion that NoSQL is an open-source phenomenon (Fowler & Sadalage, 2012). Most NoSQL databases are driven by the need to run on clusters, and this is certainly true of those that were talked about during the initial meetings about NoSQL. This has an effect on their data model as well as their approach to consistency. Relational databases use ACID transactions to handle consistency across the whole database. This inherently clashes with a cluster environment, so NoSQL databases offer a range of options for consistency and distribution. NoSQL databases operate without a schema, allowing freely adding fields to database records without having to define any changes in structure. This is particularly useful when dealing with non-uniform data and custom fields which force relational databases to use names like customField6 or custom field tables that are awkward to process and understand. March 2009 InfoWorld article entitled NoSQL Databases Break All the Old Rules (Wayner, 2009) described a set of data storage and access technologies that had been developed by Web giants like Google and Amazon and were being adversely impacted by the open-source software community. Since then, the term NoSQL database has become something of a battle-cry, a marketing meme, and a label attached to more than a hundred products, some of which pre-date the label by many years (Edlich, 2012). Anything that defines itself by what it’s not is literally unbounded, so it’s unsurprising that even the meaning of the term—No SQL or Not only SQL—is also morphing.
Relational Database Management Systems (RDBMS).
A relational database management system (RDBMS) is a software application tool. It provides the capabilities of controlling, managing, and administrating an organization’s data storage. It is the tool that utilized to create a relational database using Structured Query Language (SQL). Atomicity, Consistency, Isolation, Durability (ACID) is a concept that ensures the reliability of database transactions processing. A transaction is a database operation (Brewer, 2000).
Atomicity: Everything in a transaction succeeds lest it is rolled back. SQL carries this principle internally. An INSERT statement inserts an entire set of rows into a table; a DELETE statement deletes an entire set of rows from a table; an UPDATE statement deletes and inserts entire sets (Celko, 2013).
Consistency: A transaction cannot leave the database in an inconsistent state. In SQL this means that all constraints are TRUE at the end of a transaction. This can be because the new state of the system is valid, or because the system was rolled back to its initial consistent state.
Isolation: One transaction cannot interfere with another.
Durability: A completed transaction persists, even after applications restart.
Beyond ACID, there are three core systemic requirements that exist in a special relationship when it comes to designing and deploying applications in a distributed environment (Brewer, 2000). The three requirements are: Consistency, Availability and Partition Tolerance or CAP.
Consistency: A service that is consistent operates fully or not at all.
Availability: means just that the service is available to operate fully or not at all.
Partition Tolerance: means that a given system continues to operate even with data lossor system failure.
Key Advantages of NoSQL.
The key advantages of NoSQL include:
Schema-less: Almost all NoSQL implementations offer schema-less data representation.
Less time
Speed
Scalability
RDBMS VS. NoSQL.
Many aspects compared between the traditional RDBMS solutions and NoSQL databases. Table 1 illustrates the main difference between the traditional relational databases management systems (RDBMS) and NoSQL in terms of flexibility, query
complexity, and scalability. These features are qualitative in nature the draws the outline of each type key characteristics.
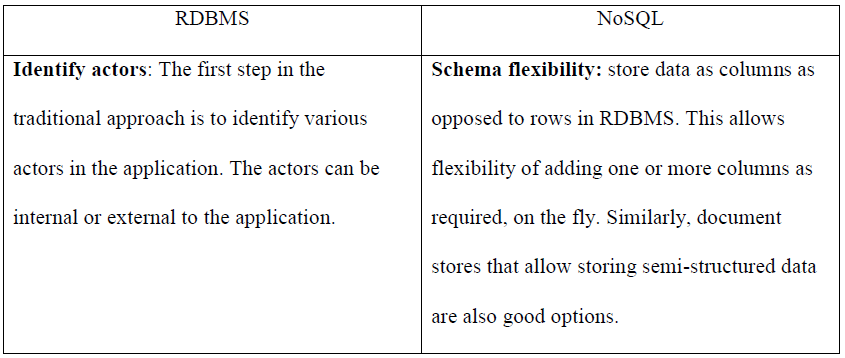

Table 1. Comparison between RDBMS and NoSQL
NOSQL Categories.
In this section, the main NoSQL databases and their application are identified. Worth noting that Key-values databases and Document databases are more mature than the Graph databases in terms of years of development, commercial brands, the variety of vendors, and years of accumulated knowledge.
Key-Value Stores.
Key-value stores are the simplest NoSQL data stores to use from an API perspective. The client can either get the value for the key, put a value for a key, or delete a key from the data store. It allows the storage of a value against a key. Similar to a document store, there is no need for a schema to be enforced on the value. However, there are few constraints that are enforced by a key-value store (Vaish, 2013). Figure 5 shows example of a set value against a key.
Figure 5. Example of Set a value against a key
Advantages of Key-value Stores:
Consistency
Transactions
Optimized Querying
Key-value stores Databases are good for:
Session information
User profiles
Shopping Cart
Document Databases.
The database stores and retrieves documents, which can be XML, JSON, BSON, etc. These documents are self-describing, hierarchical tree data structures which can consist of maps, collections, and scalar values. The documents stored are similar to
each other but do not have to be exactly the same. Document databases store documents in the value part of the key-value store; think about document databases as key-value stores where the value is examinable (Sadalage & Fowler, 2012). Even though the documents do not follow a strict schema, indexes can be created and queried.
Advantages of Document Databases:
Consistency
Easy use for web-based applications
Schema-less
Easy to define
Scaling
Document Databases are good for:
Event logging
Content Management System (CMS)
Web analytics
E-commerce platforms
Column Oriented Databases.
Column stores have been in development since early DBMS days. TAXIR, a biology information-retrieval-focused application, was the first application using column-oriented stores way back in 1969 (Vaish, 2013).
Graph Databases.
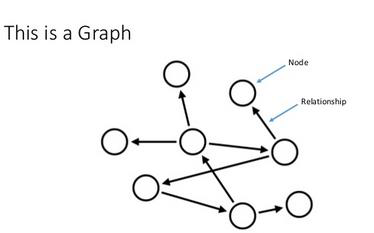
A new kind of database called a “graph’ database has recently emerged. A NoSQL database is a graph databases are noticeably post-relational data stores, because they evolve several database concepts much further while keeping other attributes. They provide the means of storing semi-structured data but extremely connected data efficiently and allow the user to query and traverse the connected data at a very high speed and efficiency. Graph databases, as Figure 6 illustrates usually consist of nodes connected with directed and labeled relationships. In property graphs, both nodes and relationships can hold arbitrary key/value pairs. Graphs form a sophisticated network of those elements and ease the process to model domain and real-world data. The graph is a structure close to the original structure which is a big difference from traditional databases. Unlike relational databases, which rely on welldefined schemas to model data, graph databases are schema-free and put no constraints onto the data structure which open more space for database architects to be creative. Relationships can be added and changed easily, because they are not part of a schema but rather part of the actual data. Figure 6 illustrates an example of how the nodes and relationships connect.
Figure 6. Visual Example of an actual Graph data model
Figure 7 shows that the graph involves equation vertices and edges. Vertices (Nodes) includes the following: unique identifiers, outgoing edges, incoming edges, and key/value pairs. While the edges (relationships) consist of: Unique identifiers, outgoing vertex (node), incoming vertex (node), and again key/value pairs.
Figure 7. Graph theory equation
Graph databases are based on algebraic equations while relational databases are based on sets, graph databases are based on graph theory, a branch of discrete mathematics. A graph database management system (henceforth, a graph database) is an online database management system typically contains the commands that Create, Read, Update, and Delete. Graph databases are generally built for use with transactional (OLTP) systems. Accordingly, they are normally optimized for transactional performance, and engineered with transactional integrity and operational availability in mind. A graph has two things in it. There are edges (or arcs) and nodes (or vertices); the edges are drawn as lines that connect nodes, which are drawn as dots or circles. Nodes are abstractions. They usually (not always) model what would be an entity in a RDBMS. In fact, some of the power of graph theory is that a node can model a sub graph. A node may or may not have “something inside it” (electrical components) in the model; it can just sit there (bus stop) or simply be (transition state). A node is not an object. Objects have methods and local data inside them. Other examples of graphs are:
Schematic maps: the nodes are the bus stops, towns, and so forth.
Circuit diagrams: the nodes are electrical components.
State transitions: the nodes are the states.
Edges or arcs connect nodes. They are drawn as lines that may or may not have an arrow head on them to show a direction of flow when the edges have arrows, the graph is called a “directed” graph otherwise it is called un-directed graph. They may also contain weights denoting the strengths of the relationship between the nodes. In schematic maps, the edges are the roads. They can have a distance or time on them. In the circuit diagrams, the edges are the wires that have resistance, voltage, etc. Likewise, the abstract state transitions are connected by edges that model the permitted switch paths. In one way, edges are more fun than nodes in graph theory. In RDBMS models of data, an unspecified single relationship between tables exists in the form of a REFERENCES clause. In a graph database, there are multiple edges of different kinds between nodes.
At the highest level of abstraction an edge can be directed or undirected. In terms of maps, these are one-way streets; for state transitions, this is prior state–current state pairs and so forth. Undirected graphs is preferable since the math is easier and there is often an inverse relationship of some sort (e.g., “employer–manager” in the case of Jose Mourinho and Jorge Valdano).
Graph Databases Pros and Cons.
There are several pros and cons associated with graph databases, the pros are a powerful data model that is not limited with any schema constrains, connected data that have many layers and levels of details and properties, and locally indexed inside the database architect, and easy and flexible to query. Nevertheless graph databases do have multiple cons, too much sharding either horizontal or vertical partition of the data inside the graph database, and a very diverse approach from relational database concept
Graph Database Domains.
Many applicable industries or solution landscape can be deployed using the graph databases, impact analysis (network, software), logistics, supply chain for package routing, recommendation systems (dating, social…etc.), master data management, financial especially fraud detection. In this section we have highlighted the main challenges in designing graph databases. To this end, three specific challenges were targeted by this research study – data models, storage models and index structures (Pardede & Sakr, 2011). Graph databases has attracted vast research attention, but has still eluded strong foundations or an overarching best practice or design principles. Research and commercial interest in graph databases is still increasing as of this writing. As the amount of data grows and the need for identifying patterns and extracting semantics becomes stronger, graph data management becomes an imminent challenge (Pardede & Sakr, 2011).