Neo4j
Neo4j is the leading application of a property graph database. It is written mainly in Java and leverages a custom storage format and the facilities of the Java Transaction Architecture (JTA) to provide XA transactions. The Java API offers an object-oriented approach to manipulate the nodes and relationships of the graph (Pollack; Risberg; Hunger; Brisbin; & Gierke, 2012). Traversals are expressed with a fluent API. Being a graph database, Neo4j offers a number of graph algorithms like: Shortest path, Dijkstra, and A* out of the box. Neo4j integrates a transactional, pluggable indexing subsystem that uses Lucene as the
default. The index is used primarily to locate starting points for traversals. Its second use is to support unique entity creation (Pollack; Risberg; Hunger; Brisbin; & Gierke, 2012). Neo4J provides a web interface for statistics about the database. In the data browser, it is possible to search for nodes by ID, or with index lookups, and with cypher queries, and switching to the
graph visualizer with the right-hand button for visually exploring the graph. The console allows the user to enter Cypher statements directly or issue HTTP requests. The other great advantage is that Neo4j an open source product, hence it has a comprehensive and active ecosystem. Neo Technology, is the company sponsoring the development of Neo4j. Neo4j also comes with a variety of programming language drivers available. There are libraries for many programming languages for both embedded and server deployment mode.
List of Programming Language Drivers.
Neo4j have many addable programming language driver that includes: PHP Cypher, Python, R Neo4J, Perl, Ruby, Node.JS, Scala, and JavaScript.
Neo4J is considered a property graph, which is a “directed, labeled, attributed multigraph” that exposes three building blocks: nodes, typed relationships, and key-value properties on both nodes and relationships. Another graph model is RDF Triples, which is a URI-centered subject-predicate-object triples as pioneered by the semantic web movement. Finally there’s HyperGraph, which is a generalized graph in which a relationship can connect an arbitrary number of nodes (compared to the more common binary graph models) (McKnight, 2013). Hypergraph is a generalized graph model in which a relationship (called a hyper-edge) can connect any number of nodes. More specifically, while the property graph model permits a relationship to have a single start and end node, the hypergraph model allows any number of nodes at a relationship’s start and end (McKnight, 2013). Neo4J has a declarative Cypher query language, which makes it easier to get started for everyone who knows SQL from working with relational databases. Developers as well as operations and business users can run ad-hoc queries on the graph for a variety of use cases.
Cypher draws its inspiration from a variety of sources:
SQL
SparQL
ASCII-Art
Different functional programming
Cypher was built to create matching patterns in a graph that are bound to specified nodes and relationships and allows additional filtering and indexing of the results. Cypher has data manipulation features that allow us to modify the graph. Cypher query parts can be chained (piped) to enable more advanced and powerful graph operations. Figure 8 depicts a cypher query
code and the results after executing this query
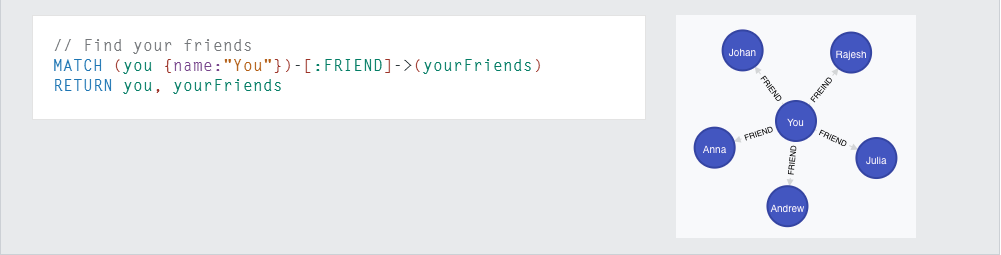
Figure 8. Example of Cypher code
The core concept is that the user describes the patterns to be matched in the graph and find starting points. The Neo4J database engine then efficiently matches the given patterns across the graph, enabling users to define sophisticated queries like “find me all the people who have friends or co-workers who have recently bought gadget products.”, Cypher supports filtering, grouping, and paging. Cypher allows easy creation, deletion, update, and graph construction.
Nodes: Cypher uses ASCII-art to represent patterns. Nodes are surrounded with parentheses which look like circles, e.g. (node) .
Relationships: The problem with the Cypher snippets is that they don’t contain information about the relationship between the nodes. So the need for describing the types of relationships in Cypher queries is essential (Onofrio Panzarino, 2014). Labels and Cypher Query Language: Labels give a very convenient feature by allowing to group our nodes. The Cypher query language is comprised of several distinct clauses.
Querying a graph involves these commands:
MATCH: Matches the given graph pattern in the graph data.
WHERE: Filters using predicates or anchors pattern elements.
RETURN: Returns and projects result data, also handles aggregation.
ORDER BY: Sorts the query result.
SKIP/LIMIT: Paginates the query result.
Updating the graph involves these commands:
CREATE: Creates nodes and relationships.
MERGE: Creates nodes uniquely.
CREATE UNIQUE: Creates relationships uniquely.
DELETE: Removes nodes, relationships.
SET: Updates properties and labels.
REMOVE: Removes properties and labels.
FOREACH: Performs updating actions once per element in a list.
WITH: Divides a query into multiple, distinct parts and passes results from one to the next.
Cypher Principles and Capabilities
Cypher matches patterns of nodes and relationship in the graph, to extract information or modify the data.
Cypher has the concept of identifiers which denote named, bound elements and parameters.
Cypher can create, update, and remove nodes, relationships, labels, and properties.
Cypher manages indexes and constraints.
Neo4j Advantages
Close to the object model
Pre materialize relationships
Traversals in linear time
Sparse, heterogeneous data and schema free
Local queries
User Interface is super friendly
