Misalignment Patterns
A parallel text (from now on it will be called bitext) is extracted from two texts, and there is no guarantee that the text segments rom each text are aligned together. In fact, there are many factors that cause and exacerbate the bitext isalignment, including the following:
1- Differences in formatting
2- Differences in segmentation rules (how text is split into sentences/segments)
3- Mistakes and omissions/additions/changes of some punctuation
4- Translation style, for example some segments and sections in United Nations
documents are sorted according to the alphabetical order in each language for the source text and the target text The following igures indicate the bitext maps for the possible misalignments within any parallel text, based on ad-hoc inspection. A itext map is a list of correct pairs of segment IDs in each text, where the x-coordinate is the source segment ID and the y-coordinate is the target segment ID. The correct alignment would be if each segment is ligned to a segment with the same ID; hence the bitext map would coincide with the diagonal, as shown in figure 1 below. The ollowing figures indicate other modes involving some misalignment, and it is likely that a misaligned document would contain a ombination of these modes, in addition to the possibility of omissions/deletions or additions. It should be noted that in this aper e are aligning English-Arabic bitexts, but in the below examples, we use English-French only to be able to visually dentify each pattern of misalignment, due to the similarity between these two languages.
1- Correct Alignment
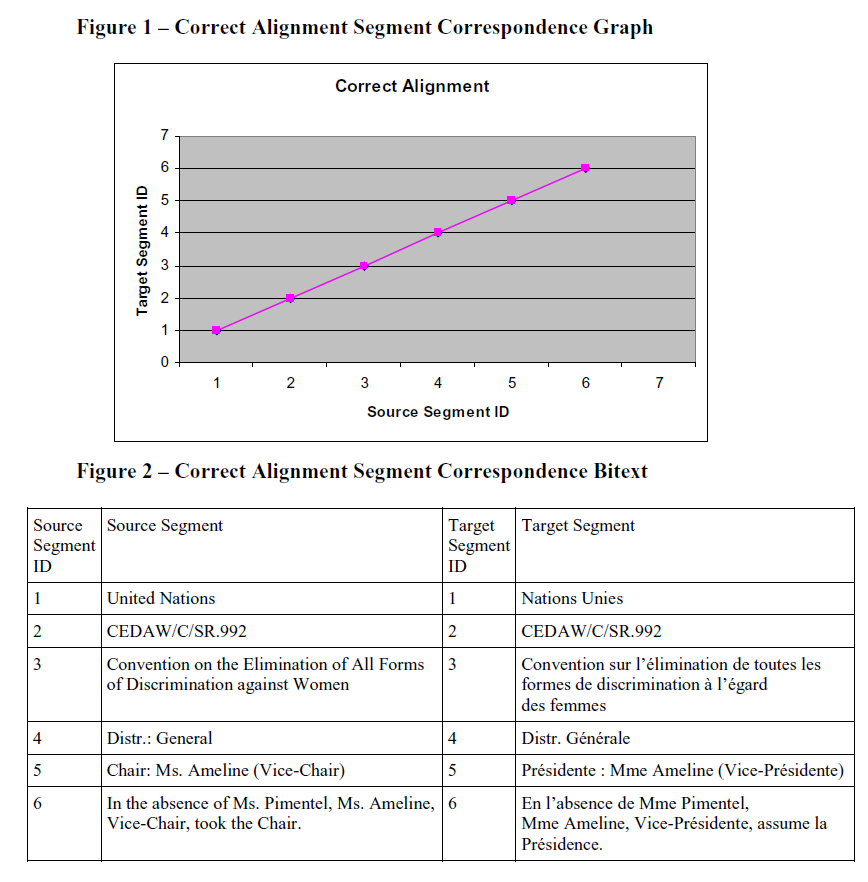
This mode simply indicates that the text segments extracted from the two documents are in the same order and they are atching each other. It is possible to do some careful effort at the early stage of extracting text from documents to make sure hat the segments are as close as possible to this mode, as it can save more effort in the alignment stage later on, but at any ate, it is unavoidable to have some misalignments within any bitext.
2- Positive Offset

Positive Offset Segment Correspondence Graph
This mode indicates that there have been some spurious segments that led to a shift in the order of segments, creating a ositive offset, where the target segments are above the diagonal. These spurious segments can be additions in the target anguage or they can be segments corresponding to other source segments somewhere in the document.
3- Negative Offset
Negative Offset Segment Correspondence Graph
This negative offset may occur due to spurious segments on the target side, but it may also occur in the cases where the ections of the documents have different order in the source and in the target document (for example if the sections are lphabetically ordered, so each document will have a different order). This particular alignment pattern is very tricky, because ome alignment approaches assume that the order of both the source and target segments IDs are always ascending, so if the egment order is returning to an earlier part of the document, probably they would be considered as deletions from one side and dditions to the other, without being correctly aligned to each other.
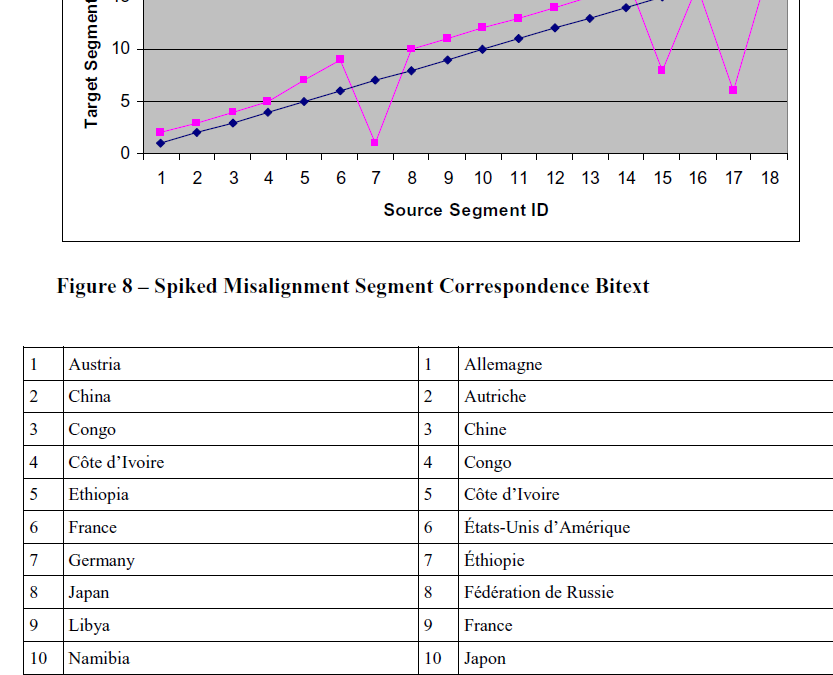
4- Spiked Misalignment
Spiked Misalignment Segment Correspondence Bitext
This spiked misalignment occurs typically within tables containing alphabetically labeled items. It can also occur due to roblems with document formatting, but usually aligned segments cluster together, so it is unlikely to have the correct segments ispersed around the document, which gives some advantage to geometric alignment approaches, because we will not be onsidering the alignment of each isolated segment, but of the segment within its neighboring segments.
5- One to Many Misalignment
One to Many Misalignment Segment Correspondence Bite
This pattern usually occurs when there is discrepancy between the segmentation rules between the source and the target, or imply because there were some line breaks in one document and not in the other.
6- Many to One Misalignment
Many to One Misalignment Segment Correspondence Bitext
This pattern is the same as the previous one, except for the fact that the source and target are swapped.