Since our approach is based mainly on lexical cues, we need a lexicon of word pairs, which is used during the alignment rocess. The lexicon can be prepared manually within CSV or XLS file and updated with new word pairs as necessary. owever, n order to generate as many word pairs automatically, we singled out a collection of reasonably aligned bitexts, and proceeded s follows:
1- Index all the words in the source and target segments within each document
2- Create inverted index for each word in the source and target
3- For each source word, identify a sample of the segments where it occurs, and the words in the corresponding target segments
4- Identify the most corresponding target word as follows:
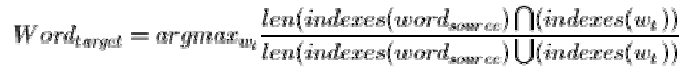
5- Collect the word pairs, and prune word pairs which have one word in common by choosing the one with the highest correspondence ratio It should be noted that the lexicon needs to be as accurate as possible, since noisy word
pairs may affect the alignment process at later stages. However, this concern should be weighed against the effect of word pair scarcity, which may leave many segments without lexical cues.
