Identification And Analysis Of Websites Selling Counterfeit Goods
Counterfeit goods are a pervasive and damaging problem in the online community, robbing brands of their revenue as well as damaging brand images. Getting an exact amount in damages of counterfeit goods is difficult, but it’s clearly an issue. When Stroppa and Specchiarello began collecting data on luxury good ads on Facebook, they found that nearly 25% of over 1,000 analyzed ads were for counterfeit goods. Knowing that search engines are the primary way to nd new websites, we wanted to see how prevalent counterfeit stores were within search re- sults. Google was used for the search engine both because of its popularity and because of the ease of use in automatically getting results via the API. While recognizing counterfeit pages from real ones is sometimes an easy task for a human, doing so in an automated fashion is challenging. This was addressed by collecting features to feed to a binary classier.
Data Collection
A script collected Google search result data between January and August of 2014. A set of 225 queries were issued to the Google Search API, and the returned web- pages (as well as their respective domains) were visited by an automated browser.
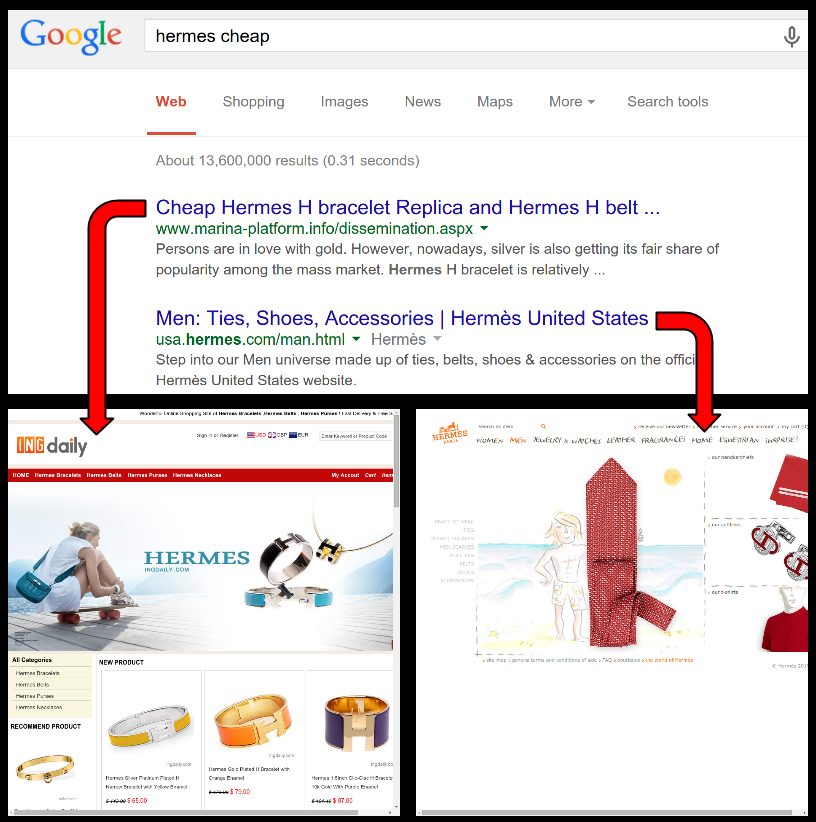
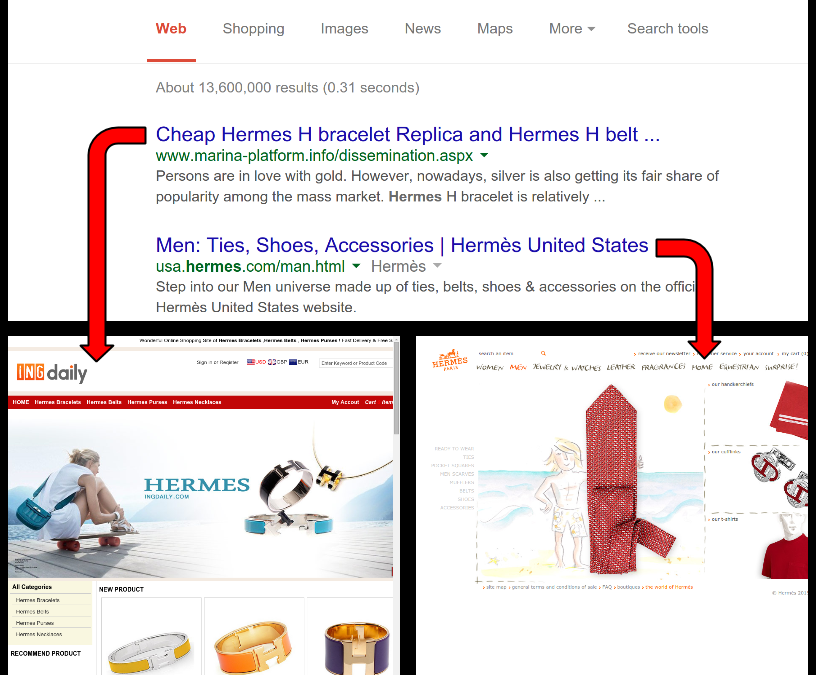
Figure 1: Example of counterfeit and legitimate websites at the top of the search results

Table 1: Innocence levels of queries expanded.
Additionally, WHOIS data was collected to discern information about the individuals registering the domains seen. The queries issued were combinations of 25 brands and search terms of varying innocence. The brands used were the 25 most seen in an initial sample of manually identied counterfeit store product listings. The search terms chosen are meant to re ect shopper intention in order to give an idea of how the shopping experience varies for shoppers with dierent objectives. Table 1 expands on the levels of innocence and search terms used for each. It should be noted that the results returned by the Google Search API will not perfectly mirror those a user would encounter performing the same Google searches in a browser. However we believe the returned results to be a close enough approximation, and the alternative (more accurate) solution of crawling Google search results in an automated browser violates Google’s Terms of Service. In order to visit the results returned by Google, Selenium1 was used to drive a Firefox browser. The automated browser visited each of the unique URLs, saving the pages’ HTML and a screenshot to disk.