In order to identify these counterfeit pages automatically, attributes of the pages are needed which suggest either sketchy or legitimate behavior. I developed a feature set based on the manual inspection of many counterfeit sites along with code to reliably extract said features from visited webpages. These extracted features are fed to a classier written by SMU doctoral student Jake Drew to make judgment calls automatically on a per-URL basis. All of the features fall under one of three high-level categories: URL-level, page-level, and website-level.
URL-Level Features
URL-level features are the easiest to extract, as they are obtained directly from the URL string itself. The rst URL-level feature is whether or not the word \replica” appears in the URL’s fully qualied domain name (FQDN). It was a trend observed during initial manual inspection of counterfeit websites that many stores selling fakesare on FQDNs containing \replica.” The other URL-level feature considered is the length of the FQDN. From manual inspection, counterfeit stores appear to have much longer URLs, often comprised of long subdomain names.
Page-Level Features
Page-level features are the features seen in the HTML of the visited pages, and as such can only be collected after the automated browser visits a given URL. The rst page-level feature is a count of the number of currencies (dollars, euros, etc.) accepted on the page. Authorized luxury good stores typically have a store dedicated to whichever country the visitor appears to originate from (for example offering goods in US dollars if the shopper is in the USA and in euros if the shopper is in Europe).
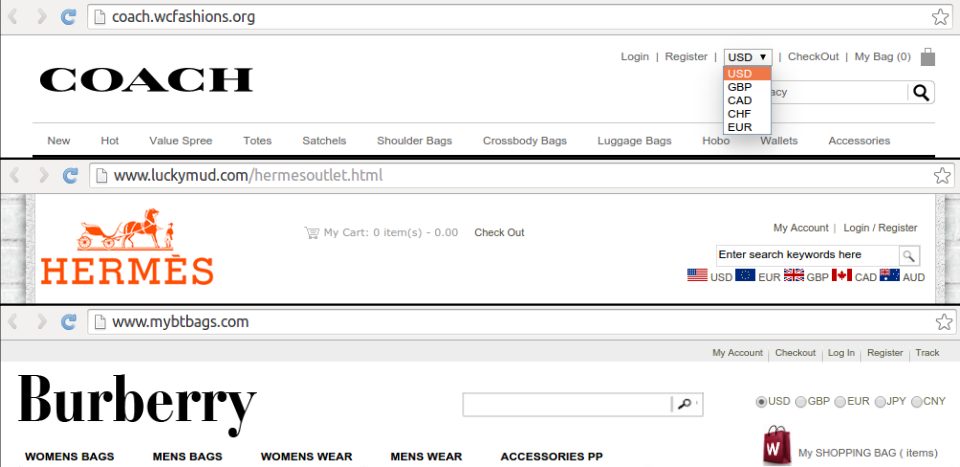
Figure 2: Three different counterfeit stores are shown demonstrating some of the ways multiple currencies are offered.
Counterfeit stores, on the other hand, attempt to serve as many people as cheaply and easily as possible resulting in single pages with drop-down menus of currencies. This is illustrated in Figure 2. Another page-level feature is the presence of large IFrames.2 IFrames allow web developers to nest webpages within webpages, acting as a window to another (possibly malicious) site. If the IFrame is \large,” the user may not realize they are looking at an IFrame. In other words, a website’s URL may re ect one location, but the user can be shown a window full of content from somewhere else entirely. We specify \large IFrame” to capture those IFrames which may be taking up most or all of the page, serving as the primary content of the webpage. The distinction is important because many legitimate widgets from sites like Facebook and Google can be displayed within legitimate (small) IFrames. As an additional measure to prevent harmless IFrames from Facebook and the like from being collected, IFrames whose source attribute are from an Alexa top 1,000 domain name are ignored.
Additionally, the percentage of savings on a page is extracted by climbing the webpage’s HTML tree looking for associated prices. This is performed to capture instances of the product’s \original” price being listed as well as its \discount” price.When the percentage of savings is very high on all items, the odds are that it is indeed too good to be true. Relating to this, another feature collected is the number of times a duplicate price is seen. This means that if the exact price $65 is seen three times on
a page, there are two duplicate prices. This is included due to a trend we noticed that counterfeit stores seem to often \copy and paste” products within a page, replacing only the images and item names.
A trend we also noticed during manual inspection was that some of the lesser- quality counterfeit stores would include an email address from Yahoo, Hotmail, or GMail. Clearly any emails listed on an official luxury brand’s websites are not going to be from a free email provider. This led to a Boolean feature specifying whether or not any emails from one of the previously mentioned domains was seen.
Counterfeit stores will often offer a wide variety of brands, and to detect this another feature we collect is the number of unique brands mentioned in a page’s HTML. If a store lists ve Gucci purses and one Hermes bag, our \unique brand term count” for the page is two. Similarly, the domain of every URL is visited separately to check for any mention of a brand (Figure 3). This is useful when trying to determine whether the root of the webpage was set up with the intention of selling goods or whether the store is limited to certain pages/subdomains (indicative of being hacked). Sometimes pages which housed counterfeit stores have been caught before our scripts visit them and will contain takedown messages from websites such as http://servingnotice.com/ or http://gbcinternetenforcement.net/ – we have a feature indicating whether the content appears to be consistent with one of their

(a) A counterfeit store found selling replica watches.
(b) Visiting the top-level page of the website reveals nothing store-related.
Figure 3: An example of the a website’s top-level page containing no mention of brand. This is one way to detect that the site is likely compromised.
takedown pages as well.
Website-Level Features
Website-level features refer to meta-data about the website as a whole, referring specically to the website’s Alexa rank (our feature being a Boolean check of whether the website is in the top 100,000) as well as information from its WHOIS documen- tation. WHOIS documents are generated when a domain name is registered, and contain information concerning the registrar used as well as information about the person who bought the domain.
The website-level data which we extracted from WHOIS comes from three elds (when present): the website’s creation date, the registrant’s name, and the registrant’s country. We use the creation date to establish a website’s age, and create a Boolean feature indicating whether the site is under one year old or not. Secondly, a Boolean feature \PrivateOrChina” indicates whether the domain was registered privately (based on the registrant name) or in China (based on the registrant country). Typically, websites selling domain names will offer the option at checkout to protect the registrant’s identity for an additional charge (register privately) – this is re ected in the registrant name. The registrant name for a privately purchased domain will
say something along the lines of \Registered privately by…” In figure 4, the user did not register the domain privately, but he did register it from China.