The sequence of steps to get the best matches from target images for a query image is called the retrieval pipeline. The retrieval pipeline has multiple steps or components. The features of the image database have to be extracted offline and stored in a database. For every query image, the feature has to be extracted and similarity has to be computed across all of the target images. Then the images can be ranked for final output. The retrieval pipeline is shown here:
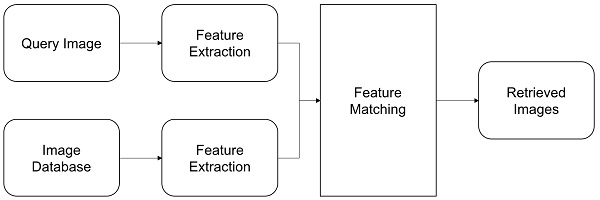
The feature extraction step has to be fast, for which TensorFlow Serving can be used. You can choose which features to use depending on the application. For example, initial layers can be used when texture-based matching is required, later layers can be used when it has to be matched at an object level.

