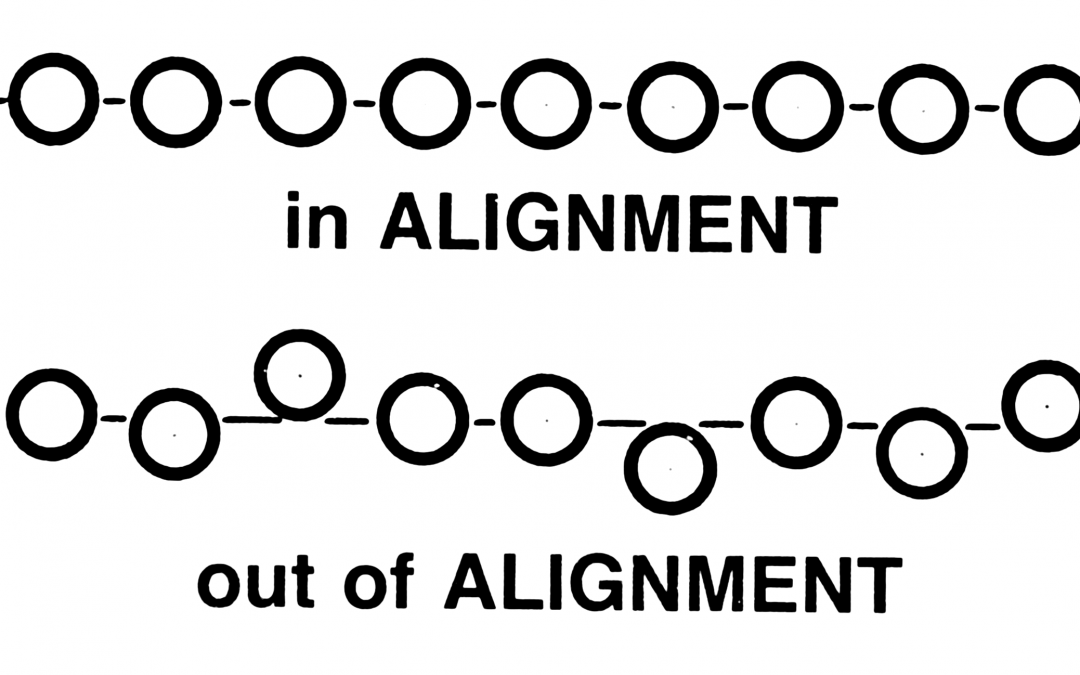
Alignment Challenges
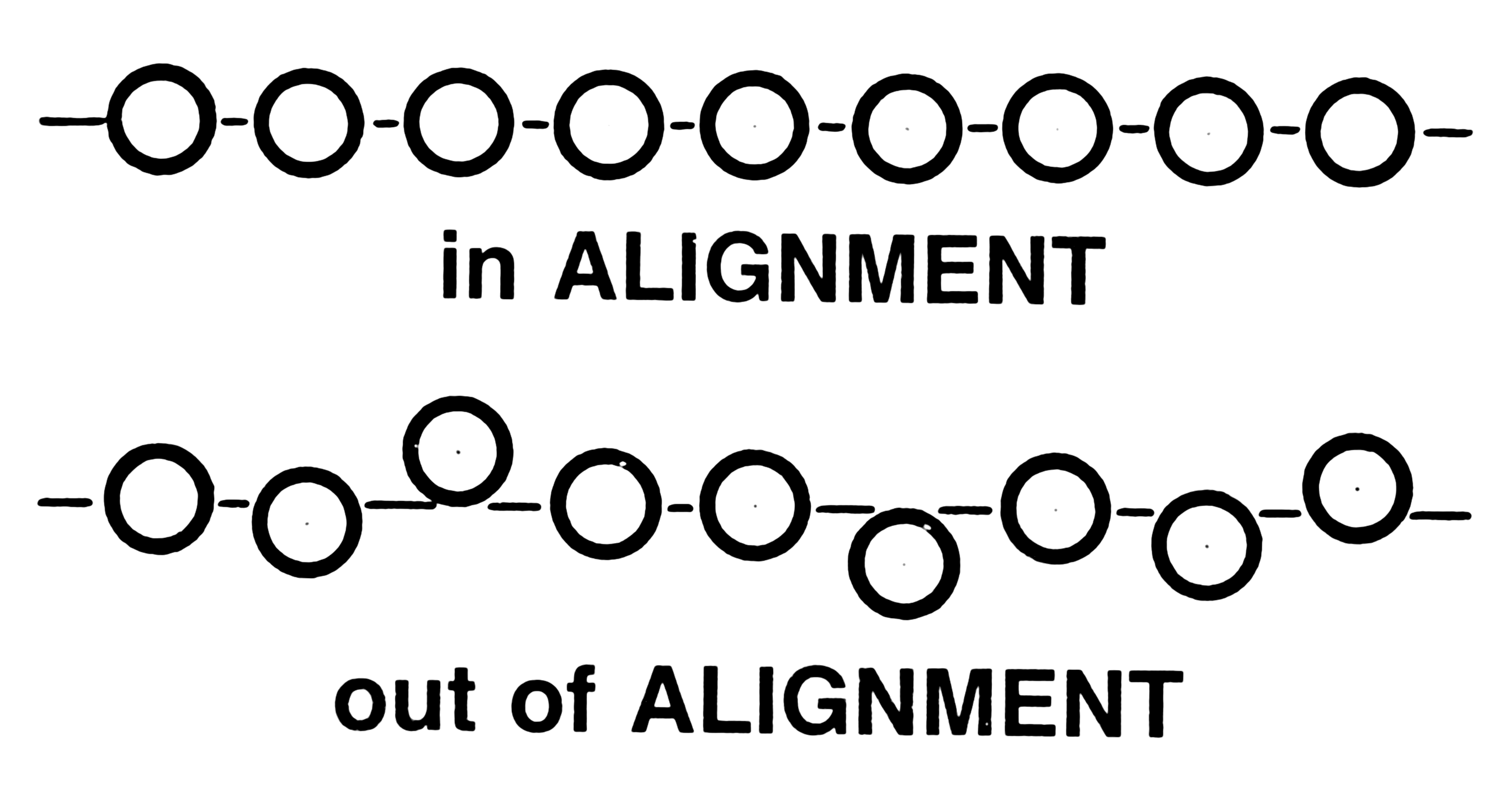
Alignment
The main challenge for alignment is that sentences/segments do not necessarily map one to-one, and there are many possible atterns for misalignment, as will be shown in the following section. The bottom line in the alignment process is to dentify certain cues, from which it would be possible to tell which segments align to which. Among the most obvious cues are he sentence lengths (the number of characters or words in the sentence); where shorter source sentences align to shorter arget sentences and longer source sentences to longer target ones. However, some factors may inhibit the effectiveness of the ength criteria; e.g. consecutive sentences with similar lengths, inconsistent length distributions (such as when expanding n acronym). Also, it can also be the case that source sentences and target sentences follow the same length distribution but hey are not actually translation of one another (as in the case for alphabetical ordering of each set of segments). Alternatively, sing lexical cues can help provide more confidence about the sentences being more likely translations of one another. The ajor drawback cited by almost all lexical-based approaches is that there are heavy processing requirements and the alignment rocess is generally much slower than the length based approaches. The problem also with lexical cues is that they are not lways available, where they should be available in machine readable format (Machine Readable Bilingual Dictionaries) (Melamed, 1996). Even with the availability of such dictionaries/lexicons, it may often be the case that the words in the source egments are context sensitive or are within idiomatic expressions so their typical corresponding words will either be absent rom the correct target segment or they would map to wrong segments. This is in addition to the typical problem that there will e many consecutive sentences which do not have words within the lexicon, so they may be described as “text deserts”, where here are no cues to know which segment map to which.In addition to the above mentioned challenges, there are more specific challenges within English-Arabic pairs, and also with United Nations documents.
Arabic-Specific Challenges
1- Arabic morphology: The affixation system in Arabic is not straightforward, as we can see from the example in table 1, where one English word can correspond to many Arabic tokens, which are essentially various forms of the same word.
Complexity of Arabic Morphology
Report Taqrir/تقریر
Submitted a report Taqriran/ تقریرا
His report Taqrirahu/تقریر ه
Her report Tarqiraha/تقریر ها
And their report wTaqrirahum/وتقریر هم
In my report bTaqriri/بتقریری
And to our report wlTaqrirana/ولتقریرنا
The report alTaqrir/التقریر
So, if the word pair in our lexicon is Report:Taqrir/تقریر , we will not be able to match the
other forms. So, the challenge is to be able to systematically stem any word consistently
to its base form.
2- Arabic Orthography: Some lexical-based approaches rely heavily on cognates to substitute/complement the use of lexical cues; however, this applies mainly to similar language pairs; e.g. English-French, but not to languages with completely different orthography, such as English-Arabic. 3- Arabic word order: Some geometric approaches ssume the correct alignment would have the words/tokens in the most linear fashion. owever, this is not the case in English-Arabic pairs, on two counts at least: – English entences follow the Subject-Verb-Object (SVO) order, while Arabic sentences typically ollow Verb-Subject-Object (VSO) order.
– English Adjective Phrases are the exact opposite order of the corresponding Arabic
Phrase, as in the below example (notice that Arabic text goes from right to left):
(1) General (2) Temporary (3) Assistance العامه ( 1) الموقۀ ( 2) المساعده )3)
Word order Difference between English and Arabic
General (1) Temporary (2) Assistance (3)
المساعده ( 3( المساعده ( 2) الموقۀ ( 1) العامه
4- Arabic length considerations: While typically Arabic sentences are shorter than English entences, there maybe certain situations where the Arabic sentence is considerably longer, as shown below: Cases where English sentences are longer than rabic sentences Case English Phrase Arabic Equivalent
For certain new terminology Gender Mainstreaming تعمیم مراعاه المنظوره الجنسانی
For acronyms UNDP برنامج الأمم المتحد الانمائی
United Nations Specific Challenges
There are many editorial considerations within the United Nations documents that cause and exacerbate the problem of misalignment, for example: 1- Alphabetical listing: ountries (and other entities) are typically sorted according to their alphabetical order. This eans that their order in each language is different. 2- Sections displacement: this can also e dependent on the alphabetical sorting of the section header. Some alignment pproaches assume that segments IDs are continuously increasing, while in situations like hese it can be the case that as we progress with the source segments and find ncreasing target segments we may encounter a new section that is at earlier part of the ocument and hence has lower target segments IDs, which can be shown in the negative ffset pattern, a misalignment patterns in the following section.
